It is tough being you. So many friends with so many personal details to remember & so little time. Maybe you should start keeping notes?
Row-oriented Databases
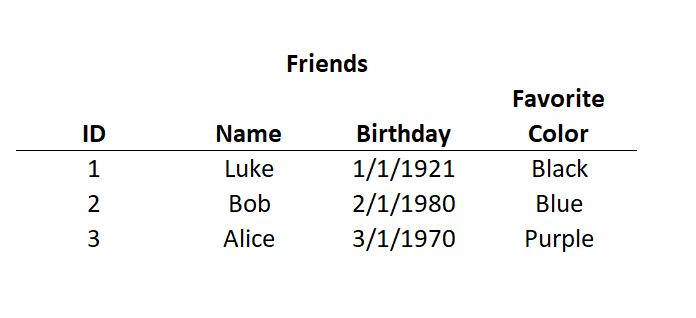
Here is one way:
Document-oriented Databases
Maybe you don’t like the whole row thing and you’d rather catch information a bit different.

Obviously both are databases. An example of the first or relational/row-oriented is MySQL, the second document-oriented is MongoDB.
As you are keeping track of your friends, you’ll find it nice that the 1st is neatly organized and has a nice layout (or schema) but it is a bit slower because you have to set up all the details and decide data types & table structures.
The document version is nice since it is fast and you are not bound by the rigid structure, for example you could add your friend Luke’s interests rather easily without setting up a new column for everyone.
Let’s say though that instead of tracking that data on your friends you were loading it all to a website. The people who work at the website and receive that data would be much more interested in analyzing information across their contributors vs. just recalling some friends names and birthdays.
This is where columnar databases have begun to turn everyone’s heads. They are blazing fast compared to their dinosaurian relational database cousins. Why?
Column-oriented Databases
To compare: relational or row-oriented databases write new entries the same way you are reading this sentence. Using our example at top: ID: 1 | Name: Luke | Birthday: 1/1/1921; (then write:) ID:2 | Name: Bob | Birthday: 2/1/1980; etc. This is great for getting data written on to a disk but not as great for retrieving it. Plus, these are often written across different disks on a server.
When you ask a program to retrieve say a minimum birthday from your database, it has to pick up all the rows across multiple disks when all it really needs is the birthday entries.
In contrast, column-oriented databases write new entries with all the same fields together in their own files and each column on the same disk. Then when you ask the computer to find the maximum birthday it only has to pick up the one file from the one disk it lives on. This is a trivial difference with our 3 entry example, but when you have billions of rows the impact gets serious.
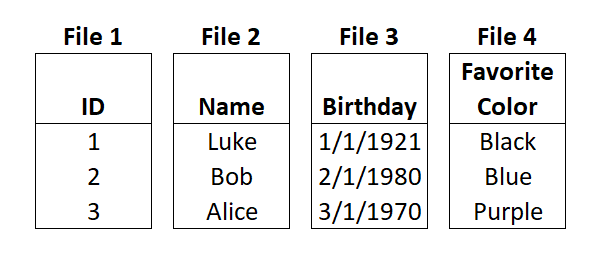
But it doesn’t stop there. Column-oriented databases also do a bunch of pre-work on the columns so they are even faster to calculate. In the birthday example they would store a version of the column (called a projection) sorted high to low & low to high. Others alphabetically ascending and descending, etc all to make each query ready for whatever the analyzer asks for.
Snowflake, Amazon Redshift & Google BigQuery are all driven by column-oriented databases.
(This article does a great job taking this topic a click deeper: https://dataschool.com/data-modeling-101/row-vs-column-oriented-databases/)
So What?
Consider at the outset whether your architecture should use row-oriented, document-oriented or column-oriented databases for your respective needs. Each are imperfect in their own ways, but you want to make sure your use case aligns with the value each of them brings.
For speed when it comes to analyzing large data sets column-oriented is and will be a dominant trend in the future (If the sound of the stampeding horde of companies rushing to adopt column-oriented databases is not enough to point to the value).



